
Optimize Data with Microsoft Fabric Spark Pools 2023
Customize Spark Pools in Microsoft Fabric for optimal analytics performance and efficiency.
Discovering new features within analytics platforms can substantially improve data handling and insights extraction. In a recent "Guy in a Cube" YouTube video, Patrick dives into the intricacies of Spark Pools within a specific analytics tool. He begins by discussing how users can initiate their analytics endeavors swiftly with a starter Spark pool available in the platform.
Data Analytics with Spark Pools
Spark pools are a fundamental component in the data analytics space, offering a managed, scalable, and optimized environment for processing large volumes of data. These dedicated resources are instrumental in performing complex analytics tasks more efficiently. As demonstrated in the Guy in a Cube video, understanding and customizing these pools can lead to significant improvements in data processing workflows. Ease of use, combined with powerful scaling options, ensures that data scientists and engineers can focus on insights and innovation rather than infrastructure management. This ability to adjust and scale computing resources on-demand is a cornerstone of modern data analytics, providing the agility and performance necessary to handle ever-increasing data workloads.
Spark Pools in Cloud Data Platforms
Patrick introduces the concept of custom Spark pools in the context of cloud data lakehouses, specifically focusing on the ease of starting with a default pool.
He demonstrates how these pools can be personalized and set as the standard for a particular workspace environment. Customization allows for better management of data analytics tasks, enhancing efficiency. The article, dated November 20, 2023, offers guidance on configuring starter pools on a major cloud platform. It serves as a walkthrough for users who need to tailor Spark clusters on the platform to meet their specific analytic needs.
Starter pools on this platform allow users to immediately utilize Spark sessions. This on-demand accessibility accelerates insights derivation since there's no need to wait for node setup. Such pools already contain Spark clusters that are continuously operational, using mid-range nodes that scale up as needed. It indicates a user-centric design that focuses on data-led insights with minimal delays.
Users are permitted to set autoscaling parameters by specifying the maximum number of nodes. The solution smartly scales the nodes up or down according to the compute requirement changes, thus ensuring optimized resource management.
Another aspect is the flexibility in executor limits within these pools. With dynamic allocation, the system adapts executor numbers based on the job's demands and data volume. This dynamic is crucial for users to concentrate on their analysis without the hassle of system optimization.
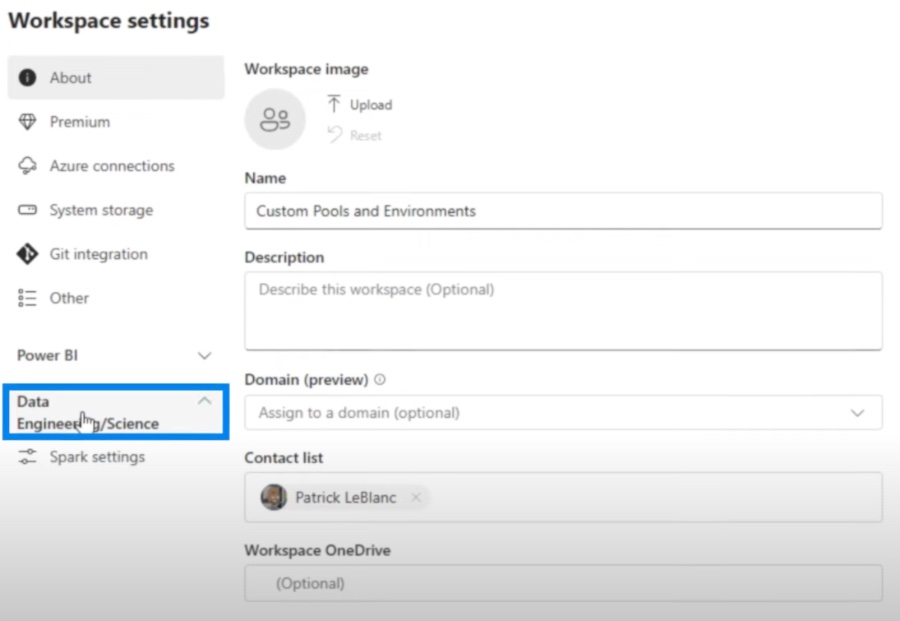
However, it's noted that adjustment of these pools requires admin access, indicating a layer of control for configuration stability. To manage these settings, users must navigate through various options within the workspace configurations.
The video describes how to access and modify Spark pool settings, providing a visual aid on navigating the platform's interface. The guide outlines default configurations and limits for various optimizations. These details are crucial for admins to tailor the environment according to the capacity and workloads they handle.
Nevertheless, certain limitations exist, such as delayed start times in certain configurations. The video explains this by focusing on issues encountered with single-node setups within these initial pools. This is a notable concern that users need to be aware of, as it impacts the performance of workloads geared towards data engineering and data science.
- Customizing starter pools requires administrative access.
- To manage a starter pool, navigate to Workspace settings and adjust under Data Engineering/Science settings.
- Users can control node and executor specs for optimal performance.
- Single-node configurations may result in slower session starts, an important consideration for performance.
The tutorial underlines the flexibility and customization options available for admins in managing cloud-based data analytics environments. It succinctly addresses the balance between ease of use and nuanced control, providing users with detailed steps to tailor their analytic experiences to their unique project demands.
The Role of Cloud Data Lakehouse Environments
Cloud data lakehouse environments revolutionize the way organizations handle big data. These platforms, like the one discussed in the video, offer starter pools with pre-configured Spark clusters. These enable immediate data processing activities, enhancing productivity and optimization.
Users benefit from the scalability and dynamic allocation, which pave the way for efficient resource management during data engineering or science workloads. Although customization of these pools requires administrative authority, the platform simplifies the user experience through a structured and intuitive interface.
Such big data solutions are integral in today's data-driven business landscape. They empower organizations to quickly derive insights and adapt to ever-chaning analytics demands, demonstrating the continued innovation in cloud data management technologies.

Read the full article Exploring Custom Spark Pools in Microsoft Fabric Lakehouses
People also ask
What is a spark job definition in Microsoft fabric?
A spark job definition in Microsoft's context typically refers to a configuration or a set of parameters that define how an Apache Spark job should run within Azure Synapse Analytics or Azure Databricks, which are part of Microsoft's data and AI services. Spark job definitions include details such as the type of task to perform, the data sources to be used, the computing resources to allocate, and the output destinations for the job results. The term "Microsoft fabric" is less commonly used but might relate to the larger Azure ecosystem where Spark jobs are orchestrated as part of an end-to-end data processing and analytics solution.
What is a lakehouse in Microsoft fabric?
A lakehouse in Microsoft's ecosystem refers to an architectural pattern that combines the capabilities of data lakes and data warehouses, providing a unified platform for data storage, management, and analytics. In the Microsoft Azure environment, services like Azure Data Lake Storage and Azure Synapse Analytics work together to create a lakehouse architecture. This approach enables businesses to manage large volumes of data (structured, semi-structured, and unstructured) while supporting advanced analytics and machine learning workloads with the performance and optimization features of a data warehouse.
Keywords
Custom Spark Pools, Microsoft Fabric Lakehouses, Fabric Lakehouses Custom Pools, Spark Pools in Lakehouses, Lakehouse Spark Optimization, Microsoft Spark Pools Customization, Advanced Spark Pool Fabric, Fabric Spark Pool Design, Scalable Microsoft Lakehouses, High-Performance Spark Pools