
Master Dataverse Data Privacy Masking Today!
Unlock Dataverse Secrets: Learn How to Mask Sensitive Data Effectively!
Key insights
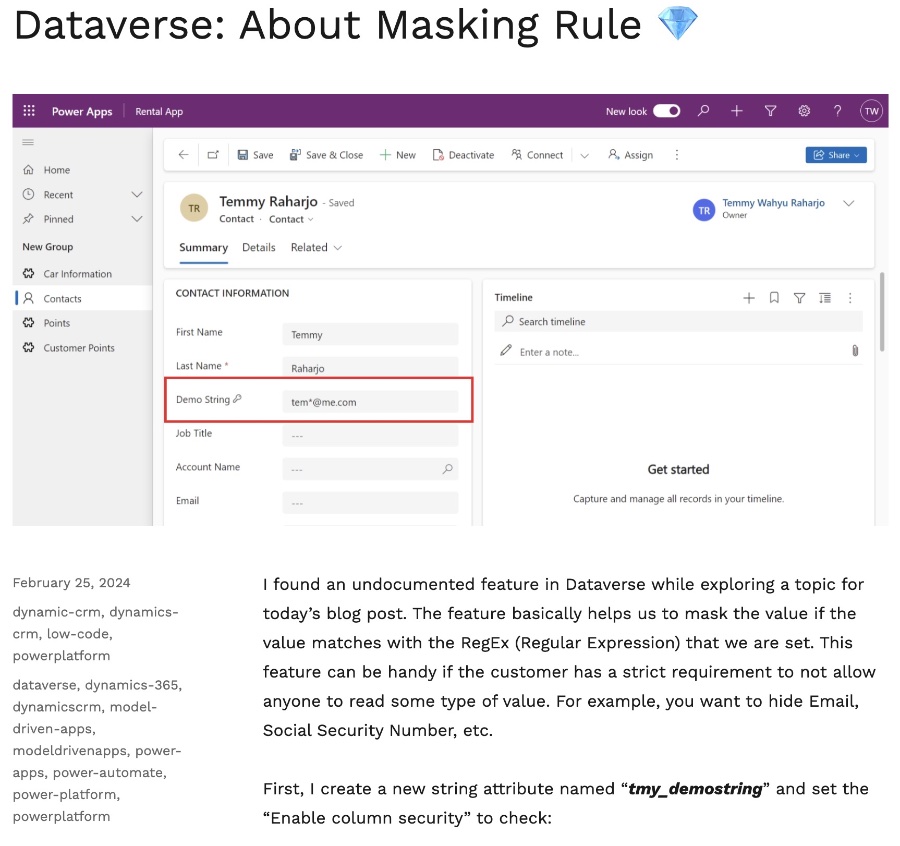
- Data Privacy Enhancement: The newly discovered feature in Dataverse allows for the masking of values matching specified Regular Expressions, bolstering data privacy.
- Masking Rules Explained: Microsoft Dataverse utilizes masking rules to secure sensitive data by replacing it with a masked version, ensuring it remains unreadable to unauthorized users.
- Rule Definition and Application: Users define a rule by specifying the data field and masking pattern. The rule is then applied when data is retrieved or exported, replacing sensitive information with its masked counterpart.
- Key Benefits: Implementing masking rules enhances security by reducing unauthorized access risks, assists in regulatory compliance, and allows data anonymization for safe analysis sharing.
- Types of Masking Rules: Dataverse offers Attribute Masking Rules for entity fields and Column Level Security Rules for table columns, both configurable to meet specific data protection needs.
Understanding Dataverse Masking Rules
Dataverse Masking Rules stand out as a significant feature in ensuring data privacy within the Microsoft ecosystem. These rules serve the critical purpose of protecting sensitive information from unauthorized access by replacing actual data with a masked version. What makes this feature particularly valuable is its flexibility and adaptability to various compliance requirements and privacy concerns.
Businesses can define masking patterns that align with their specific data protection needs, such as hiding personal information or encrypting sensitive data fields. By applying these rules, organizations can significantly minimize the risk of data exposure, align with regulatory compliance standards like GDPR, and ensure a secure environment for data analysis and sharing. Masking rules in Dataverse are user-configurable, making it easier for businesses to set up and manage their data protection strategies effectively. This approach not only enhances the security of sensitive information but also supports the responsible management and sharing of data within and outside the organization.
Read the full article Enhance Data Privacy: Master Dataverse Masking Now

Discover an undocumented feature in Microsoft Dataverse that allows for masking sensitive data. This feature is particularly valuable for ensuring data privacy. Temmy Wahyu Raharjo highlights its usefulness for businesses with strict privacy requirements.
Dataverse: Understanding Masking Rules
Microsoft Dataverse uses masking rules to secure sensitive information from unauthorized access. By replacing real data with a masked version, it prevents unwanted exposure. These rules are essential for both security and regulatory compliance.
- Protects various sensitive data types.
- Ensures regulatory compliance and privacy.
- Prevents accidental exposure of sensitive information.
Defining and applying a masking rule involves specifying data to mask and choosing a masking pattern. These patterns can range from simple replacements to more complex regex-based logic. The flexibility in defining these rules is a key feature of Dataverse.
- Define rules with specific patterns or regex.
- Apply rules to safeguard data upon retrieval or export.
The benefits of masking include enhanced security, compliance with privacy regulations, and data anonymization. These advantages demonstrate the importance of masking rules within Microsoft Dataverse for maintaining data privacy and security.
- Two types of masking rules: Attribute and Column Level Security Rule.
- Customizable masking characters and rule testing.
In a demonstration, Temmy Wahyu Raharjo showcases how to create and apply an Attribute masking rule for email addresses. This example reveals how Dataverse's masking feature can be tailored to meet specific data privacy needs.
People also ask
"What is the data mask tool for Dataverse?"
The Dataverse Data Mask tool is adept at safeguarding sandbox environments by substituting real, sensitive data with fictitious data. It employs a blend of masking, anonymization, and obfuscation techniques to protect confidential information during development, testing, and training phases.
"What are the techniques for data masking?"
Various techniques are prevalent in the data masking realm to secure sensitive information. These include Static Data Masking, which allows the creation of a sanitized database copy, Deterministic Data Masking, On-the-Fly Data Masking, Dynamic Data Masking, Data Encryption, Data Scrambling, Nulling Out, and Value Variance, each serving a unique purpose in data protection.
"Is data scramble the same as data masking?"
Data scrambling is a straightforward method of masking by transforming data into a random and indecipherable sequence of characters. Despite its ease of implementation, it is best suited for specific data types and does not offer the highest level of security, making it less favorable for protecting highly sensitive data.
"What are the benefits of data masking?"
The advantages of data masking are multifaceted, featuring enhanced security by reducing data breach risks, malware, and cyberattacks, adherence to various regulatory compliances, and safeguarding data privacy. Moreover, it facilitates the utilization of data and secure sharing with third parties while being cost-efficient.
Keywords
Dataverse Masking, Data Privacy Enhancement, Master Dataverse Privacy, Data Masking Techniques, Improve Data Security, Secure Data Handling, Privacy Control in Dataverse, Dataverse Data Protection